At 05:18 this morning nagios notified me of a failure of one of the two power feeds in Servology rack 2 at Telehouse North. The ATS in the rack reported a loss of redundancy (but as far as I can see, the input which failed was the one it was not using at the time, so it did not need to switch), and several servers with dual power supplies reported one of their two PSUs had failed. I contacted Star Europe and one of their staff discovered that a circuit breaker had tripped and switched it back on at about 07:15. This restored redundancy and I believe this problem is now resolved.
This does leave the question of why the breaker tripped. I’m not sure there’s much I can do on this front as the Star staff member couldn’t see anything untoward, but if it trips again I will have to find a way to investigate.
Late last night and earlier this afternoon there have been some intermittent faults with connectivity, mostly affecting users connecting to the internet through the Servology network using VPN tunnels, but also occasionally affecting colocated servers. I have discovered that some traffic was still passing through the backup router whose hard disk became faulty earlier this year. I don’t believe today’s problems are due to the faulty hard disk, but more likely a bug in the (very old) BGP implementation on that router, which was causing it to emit bad announcements under certain circumstances, causing other routers to drop and reestablish their BGP sessions with it. However, I believe I have mitigated the problem by adjusting some routing metrics to better ensure traffic is diverted away from the backup router whenever possible. I will now be treating the project to replace this router as very urgent.
Between about 04:53 and 05:18 this morning, 25 April 2023, there were a number of short outages in connectivity between certain destinations and the Servology network. My routers’ BGP sessions do not seem to have been interrupted and connectivity to at least some destinations seems to have been unaffected, but at least some other destinations did not have connectivity for several minutes. The outages between my remote monitoring node and the Servology network seem to have been approximately 04:53-04:54, 04:55-05:01 and 05:11-05:18. As I see no problems logged on my own equipment I can only guess these outages occurred in an upstream provider’s network.
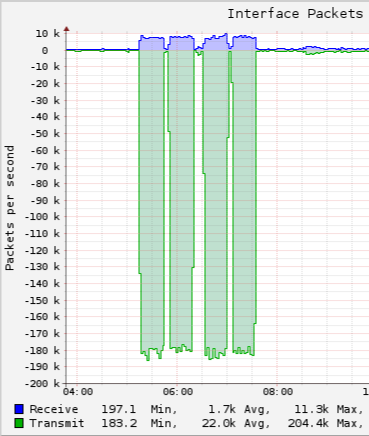
My monitoring system detected network disruption between about 07:15 and 09:30 this morning, which seems to have involved high levels of intermittent packet loss, but possibly not a total loss of connectivity at any time. It sent me several warning notifications about packet loss, some >50%, but it seems there was not a serious enough enough outage at any given time to trigger a critical alert which would have woken me up. I have not yet finished analysing the logs, but as yet I have not been able to find any evidence of problems on my own network or with my connectivity to upstream transit providers. My transit providers’ status pages do not report any problems this morning either.
Under most circumstances this would lead me to assume that the problem was closer to the network which hosts my monitoring system and not near my own network, except that during the same time-frame, (a) a customer reported problems accessing Servology-hosted services, and (b) at least one feed receiver hosted at Servology saw missing data.
I will see what else I can find out, but unless this happens again I am not sure I will be able to make any diagnosis. Apologies for the disruption; I will keep an eye on the situation.
Update: the disruption seems to have coincided with a large amount of traffic coming in from our upstreams (this is from an interface facing towards colocated servers, therefore “transmit” is data coming in from the internet, and this only shows the successfully forwarded traffic – total arriving traffic seems to have been approximately 60-70% higher than this):
Judging by the byte/packet ratio this appears to have been a huge flood of small packets, which is a weak spot with my current BGP routers – while they are able to handle large amounts of “normal” traffic (i.e. large packets for bulk data transfer), they just aren’t able to forward large numbers of small packets fast enough to keep up, hence the observed high levels of packet loss.
(As mentioned before on this site, I am working on preparing newer routers, which should be able to handle larger amounts of traffic. They are connected to the network for testing and final configuration and I hope to transfer the traffic load to them within the next few weeks, which will hopefully mitigate this kind of problem.)
Update 2023-04-01 19:05: We are again suffering huge amounts of incoming network traffic which is causing degraded performance – this will cause timeouts and other disruption to services. I have identified the traffic as huge numbers of DNS queries for random names in a specific domain. The traffic appears to be coming from a large number of different source IP addresses and is targetting the authoritative servers for the domain, so there is little way to distinguish the traffic from legitimate traffic until it reaches the target servers. I have disabled the targeted domain for the time being in case that helps mitigate the problem.
Update 2023-04-01 21:00: The client has changed the nameservers of the targeted domain(s) to point to the new distributed Servology nameserver network, which is not yet fully commissioned but which I can at least monitor, and which is hosted at other providers. This seems to have mitigated the problem – the attack traffic has shifted to the new nameservers and is no longer overloading the Servology colo network. I am sure the other, larger, providers who host the new nameservers are much better able to handle the traffic volumes involved – I have not seen any problems connecting to these other networks since the traffic shifted to them. I am going to declare this problem mitigated for the time being.
The backup Servology BGP router has suffered a disk fault which has caused its root filesystem to go read-only. This does not immediately impact its operation as a router as it does not need to write to disk for normal operation, but there is the risk that the router may fail entirely; for example if it suffers a power outage, it may not be able to boot up again afterwards.
Please note that even if this router does fail entirely, this should still not impact user-visible service; the router was already in backup mode, with traffic diverted away from it. It would normally only handle network traffic if there’s a fault elsewhere in the network. If the backup router failed it would mean that our backup upstream connection would be unusable, and we would be without redundancy for upstream connectivity and colocation routing, putting these services into an “at risk” condition.
Because this incident is effectively twice removed from actually affecting service, I have decided not to immediately replace the faulty disk, but instead dedicate time to the work to replace the faulty router with a newer machine, a project which has been underway for some time now and is close to completion.
I expect to announce maintenance windows soon to allow me to integrate the replacement routers into the existing iBGP, VRRP and VLAN/firewall setups, after which they should be able to take over the functions of the current routers.
00:07 Connectivity between Servology and the rest of the internet is intermittent and/or broken. There appears to be some kind of problem with BGP but I am not yet sure what. I am investigating urgently.
00:21 I have disconnected the Servology network from one of our upstream providers CityFibre, and connectivity seems to have stabilised via our other upstream provider, hSo. Both upstream connections appear to have been unstable so I am unsure what was happening. I will continue to investigate.
01:56 After a period of network stability I have reconnected our BGP sessions to CityFibre, first the IPv6 session which I monitored for about 20 minutes, then the IPv4 session. Both seem to be stable and I will continue to monitor until at least 02:30, being ready to shut down the BGP sessions via emergency remote access links if they appear to cause any more problems.
02:37 I have seen no further problems. The timeline of this outage appears to have been as follows: intermittent connectivity from around 23:28 on 1 February until about midnight. At this point I logged in via emergency remote access to investigate and shut down our CityFibre BGP sessions. This caused a short full outage lasting several minutes from approx 00:01 to 00:06 on 2 February. After that, connectivity appears to have been stable, including during the reconnection of the BGP sessions at 01:29 (IPv6) and 01:53 (IPv4).
Monitoring has alerted me to some network outages which occurred between about 12:30 and 13:00 today. Over the weekend I had made some changes to the way routing processes are restarted on my core routers if they become unresponsive, and I believe this helped keep the disruption shorter than last time. I believe I’ve finally pinned down the root cause of these outages. One of the core routers is getting short of memory and it seems this causes routing processes to run slowly. (The other core router has twice the memory and does not seem to be having the same kind of problems.) Protocol timers then expire, at which point other routers shut down and reestablish their associations with the problem router, causing an outage in the meantime. On its own this would not be too disruptive, but the router’s internal monitoring also detects the routing processes becoming unresponsive, so it shuts down and restarts those processes, which takes time. To mitigate the problems I have disabled a link between two core routers for now and I expect this will reduce the memory pressure and keep things running smoothly until I can implement a more permanent fix.
I have been working recently on configuring a pair of new core routers to replace the (aging) current ones. The new routers have much faster processors and 32 times the memory of the current ones, and I have been prioritising this work since the outage last Thursday, especially over the weekend. I expect to get these new routers into service very soon now which should fully resolve the recent network problems.
16:28: While working on configuring a new router it appears I have accidentally caused a network outage on the Servology network. I’m working to determine the extent of the problem and recover operation.
16:38: It appears the Servology network is entirely offline as of 16:23 today. There does not appear to be any working method to remotely access network devices to restore service. It looks like I am going to have to go to the datacentre to manually disconnect the faulty device. I’ll post an ETA here when I have it.
17:00: ETA at datacentre 18.30
18:40: arrived, gaining access to datacentre.
18:50 I’ve unplugged the problematic machine and monitoring statuses are going green. I believe the problem has been resolved.
20:00 I believe this problem is now fully resolved.
Starting around 16:04 today for IPv6 and 16:18 for IPv4, the Servology network has suffered routing problems which appear to be caused by a temporary routing process failure and restart on one of our BGP routers. I believe the problem is now resolved.
Connectivity to and from the Servology network was degraded from approximately 11:20 to 13:00 on Friday 22 July 2022, due to faulty hardware in our main transit provider’s network. Once I had determined that the problem was caused by a fault outside the Servology network, I resolved the problem by shutting down our connection to our main transit provider and failing over to our backup transit provider. Our main transit provider declared a Major Incident and worked to stabilise their network. I reestablished our connection to them the following day in off-peak hours once it became clear that their network was once again stable. This fault affected access to several (but not all) web sites and other services hosted at Servology.
Close
Ad-blocker not detected
Consider installing a browser extension that blocks ads and other malicious scripts in your browser to protect your privacy and security. Learn more.