My monitoring system detected network disruption between about 07:15 and 09:30 this morning, which seems to have involved high levels of intermittent packet loss, but possibly not a total loss of connectivity at any time. It sent me several warning notifications about packet loss, some >50%, but it seems there was not a serious enough enough outage at any given time to trigger a critical alert which would have woken me up. I have not yet finished analysing the logs, but as yet I have not been able to find any evidence of problems on my own network or with my connectivity to upstream transit providers. My transit providers’ status pages do not report any problems this morning either.
Under most circumstances this would lead me to assume that the problem was closer to the network which hosts my monitoring system and not near my own network, except that during the same time-frame, (a) a customer reported problems accessing Servology-hosted services, and (b) at least one feed receiver hosted at Servology saw missing data.
I will see what else I can find out, but unless this happens again I am not sure I will be able to make any diagnosis. Apologies for the disruption; I will keep an eye on the situation.
Update: the disruption seems to have coincided with a large amount of traffic coming in from our upstreams (this is from an interface facing towards colocated servers, therefore “transmit” is data coming in from the internet, and this only shows the successfully forwarded traffic – total arriving traffic seems to have been approximately 60-70% higher than this):
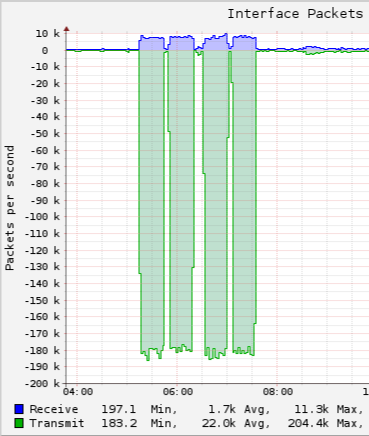
Judging by the byte/packet ratio this appears to have been a huge flood of small packets, which is a weak spot with my current BGP routers – while they are able to handle large amounts of “normal” traffic (i.e. large packets for bulk data transfer), they just aren’t able to forward large numbers of small packets fast enough to keep up, hence the observed high levels of packet loss.
(As mentioned before on this site, I am working on preparing newer routers, which should be able to handle larger amounts of traffic. They are connected to the network for testing and final configuration and I hope to transfer the traffic load to them within the next few weeks, which will hopefully mitigate this kind of problem.)
Update 2023-04-01 19:05: We are again suffering huge amounts of incoming network traffic which is causing degraded performance – this will cause timeouts and other disruption to services. I have identified the traffic as huge numbers of DNS queries for random names in a specific domain. The traffic appears to be coming from a large number of different source IP addresses and is targetting the authoritative servers for the domain, so there is little way to distinguish the traffic from legitimate traffic until it reaches the target servers. I have disabled the targeted domain for the time being in case that helps mitigate the problem.
Update 2023-04-01 21:00: The client has changed the nameservers of the targeted domain(s) to point to the new distributed Servology nameserver network, which is not yet fully commissioned but which I can at least monitor, and which is hosted at other providers. This seems to have mitigated the problem – the attack traffic has shifted to the new nameservers and is no longer overloading the Servology colo network. I am sure the other, larger, providers who host the new nameservers are much better able to handle the traffic volumes involved – I have not seen any problems connecting to these other networks since the traffic shifted to them. I am going to declare this problem mitigated for the time being.